【项目实战】德英互译NLP模型
项目报告

介绍
围绕机器翻译,对NLP知识进行了总结复习和实战。首先总结了机器翻译模型的发展历史,并对相关技术进行复习。最后使用了几个前沿的预训练模型对德英数据集进行了微调,并使用不同的分词手法和评估函数进行了对比。
发展历史
- RNN:加入了上一个隐藏层的输入以记忆历史数据,最先被提出用来解决时间序列模型的结构。但是过长的文本会导致梯度消失。
- LSTM/GRU:解决长文本问题,可提供对更久以前的数据的记忆。
- Attention机制:1. 提供弹性表达(而不是只能将文本映射为固定长度的向量) 2. 可学习全局的关系 3. 并行计算
- 双循环网络:初期的RNN只能单向循环,即只能看到前面的内容,看不到后面。双循环添加了从后向前的方向,使输出不仅依靠前面的文本还可知晓后面的内容。
- Transformer:结合上述结构的优势,生成了强大的Transformer。在Transformer基础上还诞生了BERT等强大的模型。
使用手法
主要使用基于Transformer模型T5和Transformer-align,对机器翻译任务进行迁移学习。
实验
- Dataset:Multi50k
- Evaluation:Bleu
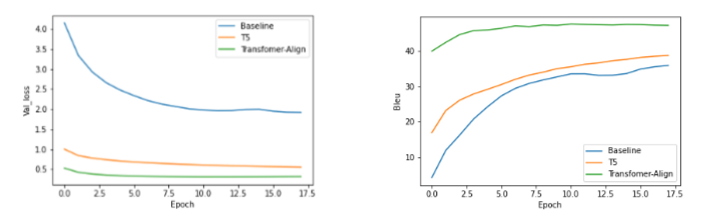
下面两张图分别是在测试集的损失变化,和Bleu的变化量。可以看出Transfromer align在本次任务中表现最好。
我们还实现了词语之间的attention值的可视化,更明显的看出每个生成词语的参考来源。