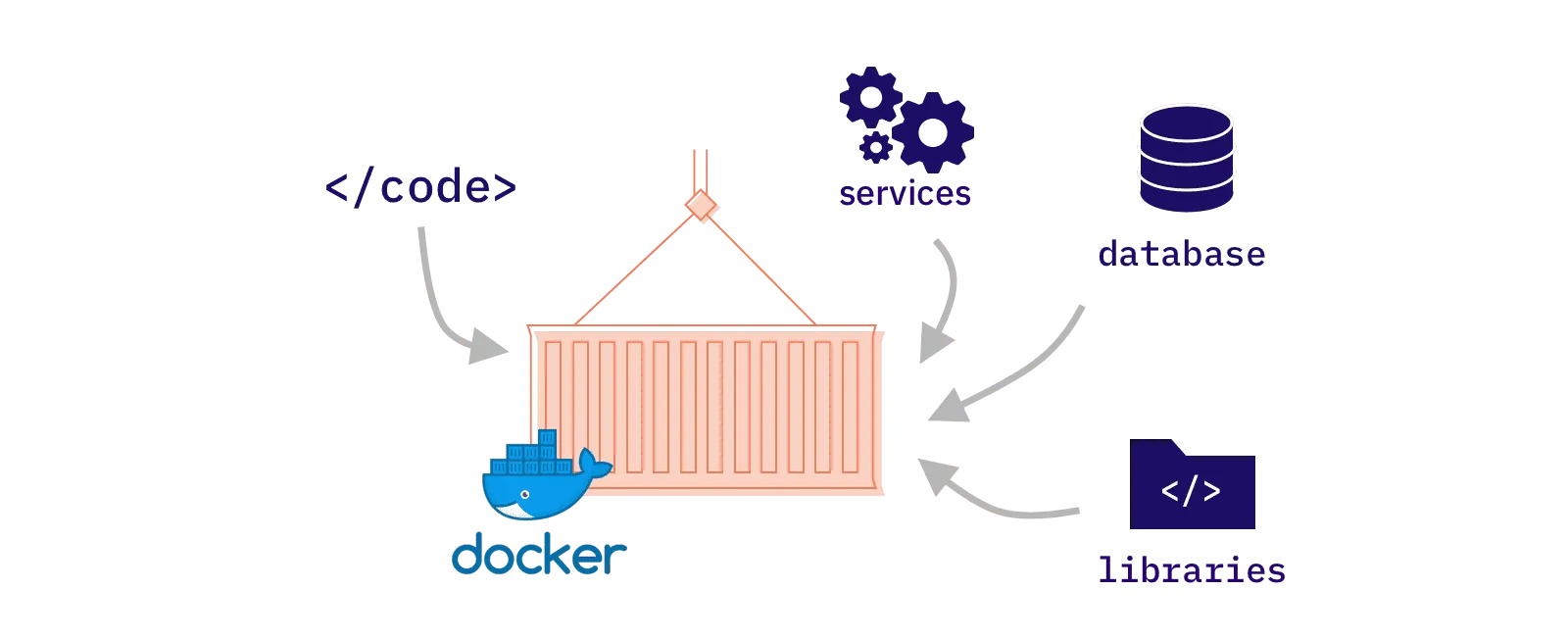
闲看-数据集会有刻板印象吗?
本来是想看Ruth Fong这位作者的一些关于可解释模型的一些论文,但是无意中看到她作为共作的讨论数据集的性别刻板印象的论文,沉迷于此看了一天倒是忘记了最开始是要看别的来着…
Meister, Nicole, et al. “Gender Artifacts in Visual Datasets.” arXiv preprint arXiv:2206.09191 (2022).
标题:Gender Artifacts in Visual Datasets论文地址:https://arxiv.org/abs/2206.09191关键词:AI fairness, gender bias, dataset analysis
0. 摘要我们已经知道性别偏差会出现在大型图像集中并且会影响下游任务模型。许多前序工作已经提出弱化这种偏差影响的手法比如尝试将性别情感相关的情报从图片里删除。为了理解这些手法的可行性和使用性,我们调查了大型图片集中究竟有哪些性别伪影(gender artifacts)。我们定义,性别伪影应该是一个
可视的并且会被现代模型学习到的
能以人类思维解释的
与性别相关的线 ...

剑指Offer-1(队列,栈,链表)
基本概念栈:先进后出
栈顶,栈底,进栈,出栈
实现方式:顺序栈(数组),链栈(链表)
两种实现方式的区别,仅限于数据元素在实际物理空间上存放的相对位置,顺序栈底层采用的是数组,链栈底层采用的是链表
应用:浏览器的回退(page.history),IDE的括号匹配
相关题目:虽然栈的运作机制很简单实现功能也较少,但由于不同于其他结构的先进后出的结构,通过主栈加辅栈的组合也能实现不错的功能
剑指09. 用两个栈实现一个队列
剑指30. 包含min函数的栈
队列:先进先出
实现方式:
列表:list和list.pop(0)
python库:collections.dqueue和dqueue.popleft()
时间复杂度的不同:list 是列表,数组移除头部元素的方式是把后面的元素全部往前移动一位,所以复杂度是 O(N) ; deque 是双端队列,底层是链表,因此头部和尾部是等价的,插入删除都是 O(1)
应用:遍历树或图时
相关题目:
链表
相关题目:
利用链表有序的特点进行遍历:
剑指16. 从尾到头打印链表
剑指18. 删除链表的节点
但是也因为有序的特点 ...

【项目实战】德英互译NLP模型
项目报告pdflink
介绍围绕机器翻译,对NLP知识进行了总结复习和实战。首先总结了机器翻译模型的发展历史,并对相关技术进行复习。最后使用了几个前沿的预训练模型对德英数据集进行了微调,并使用不同的分词手法和评估函数进行了对比。
发展历史
RNN:加入了上一个隐藏层的输入以记忆历史数据,最先被提出用来解决时间序列模型的结构。但是过长的文本会导致梯度消失。
LSTM/GRU:解决长文本问题,可提供对更久以前的数据的记忆。
Attention机制:1. 提供弹性表达(而不是只能将文本映射为固定长度的向量) 2. 可学习全局的关系 3. 并行计算
双循环网络:初期的RNN只能单向循环,即只能看到前面的内容,看不到后面。双循环添加了从后向前的方向,使输出不仅依靠前面的文本还可知晓后面的内容。
Transformer:结合上述结构的优势,生成了强大的Transformer。在Transformer基础上还诞生了BERT等强大的模型。
使用手法主要使用基于Transformer模型T5和Transformer-align,对机器翻译任务进行迁移学习。
实验
Dataset:Multi50k
Ev ...

【项目实战】考虑内容的图片缩放
项目报告pdflink
项目描述对于图片缩放,我们希望在缩放时却不影响主体的变换。一般来说,缩放技术有基于离散和连续的两种方法,离散型通常是迭代地寻找一排(或者一列)最小能量的像素,以删除在原图片中无效的像素点;连续型则通过形变等手法改变整个图片的比例。本项目基于Seam Carving [1]和 Image Warping [2]的论文进行代码的复现和结果的比较。
背景遗传算法
进化算法的一种,优化方式属于随机优化
受生物遗传算法的启发
常用于1. 非连续,非凸,非可微,非线性等难以定义的目标函数 2. 或当搜索空间过大难以使用普通优化方式的问题
过程
随机生成一批个体(individual),这一批个体形成了一个群落(population)
每个个体其实就是一个解(solution)
每个个体具有一个适应度(fitness)的评判值,代表着它对于目标问题的分数
根据适应度的高低,高适应度的个体会相互繁衍(crossover)产生后代(下一个个体),并且会进行复制(reproduce)(在迭代中被留下);低适应度的则在下一次进化中被淘汰(discard)
在产生个体时,还会有一 ...
Queue Theory
解决问题对于某个服务大厅,已知(1)单位时间内会来的客人数(2)服务客人需要的平均时间
下一个客人什么时候来?(=t时间内来客人的概率为?)
t时间后,队伍会排多长?
流程
客人到达
排队
窗口服务
离开
初始化两个重要初始化概念:1. 客人到达时间的概率分布 2. 服务时长的概率分布这两个定下来后排队所需时间和客人离开时间就固定下来了
M/M/1:到达时间和服务时长满足泊松分布,且只有一个服务窗口
M/D/1:到达时间满足泊松分布,服务时长满足固定分布,且只有一个服务窗口
泊松分布(负指数分布)性质
无记忆性(马尔科夫模型)
泊松分布就是描述某段时间内,事件具体的发生概率。
P:概率
N: 某种函数关系,
t:时间
n:数量,1小时内出生3个婴儿的概率,就表示为 P(N(1) = 3) 。
λ:表示事件的平均频率(如已知一小时内平均畜生5个婴儿则λ=5)
模拟% M/M/1 シミュレーション% イベント駆動型%シミュレーションの時間T = 100000;%客数N = 10000;% 客の構造体の定義と初期化s.arrivalTime_ = -1;s.departu ...

Collection of CGO
Collections
https://github.com/ericjang/awesome-graphics#games
https://kesen.realtimerendering.com
Image-based Editing and Reconstruction
Image stitch / photomontage
http://grail.cs.washington.edu/projects/photomontage/ Interactive Digital Photomontage
http://cs.brown.edu/courses/cs129/results/proj2/taox/ Gradient Domain Fusion Using Poisson Blending
CourseNot only the slides of courses but also lots of useful learning materials.
http://graphics.cs.cmu.edu/courses/15-463/2012_fall/463.html ...

Linear models for classification
1. Intro
goal: The goal in classification is to take an input vector x and to assign it to one of $K$ discrete classes $C_k$ where k = 1, . . . , K
Regression : take continuous values
NOTErepresentation
Two class: target variable $t \in \{0, 1\}$ such that t = 1 represents class C1 and t = 0 represents class C2
Multi class: t is a vector like (1,0,0,0,0,0…) when its class is C0
For linear regression, we only need $y=w^Tx+w_0$to obtain a real number;
For classification problem, we wish to p ...
SIFT
SIFT究竟在做什么?WHATSIFT属于传统特征提取方式,与通过深度学习的反复学习提取出的特征值不同,传统特征提取方式需要通过人工计算和模拟实验找到所需要的特征点。一个好的特征量应该具有尺度不变的性质,本文就是在解释通过怎样的计算步骤能找到这样的特征量。
WHY特征量往往被用在物体识别,并且应该是分辨度高的,以区分于杂乱的背景和庞大的数据库。
HOW我们主要使用四个步骤:1.尺度空间的极值检测,2.关键点的定位,3. 方向分配 4. 关键点描述,来提取我们所需要的特征量。
目的这篇文章帮助我们从图片中提取出图像特征,能满足即使当这个图片中某一事物或场景发生了失真,视角偏移,噪点增添或是光线改变时,也能将图片间的相关点进行对应。而且他它们是易于区分的特征,即使是从庞大的特征库中也能利用它们找到对应的真正的物体或场景。
步骤分为以下三步
尺度空间的极值提取
关键点定位
方向分配
关键点描述
这一系列的方法称作为SIFT,即尺度不变的特征转换。
1. 尺度空间的极值提取生成高斯图像、尺度空间极值提取的计算式,将使用DoG进行计算。首先我们已经知道唯一可行的尺度空间核就是高斯核,因此我们 ...
Edge Detection
1 Feature detection
Containing vast information
SO it’s important to determine
WHERE
concentrate on a part and ignore others
e.g. Object recognition: Ignore background
WHAT
Feature can be located
edge
feature points
2 Edge detection2.1 Feature
Brightness (value) changes rapidly
Differentiation (近傍ピクセルとの微分処理 )
Important feature for object recognition
Weak to noise(Because it is differentiation)
2.2 Kinds
2.3 Differentiation
Grandient
\nabla I=(\frac{\partial I}{\partial x}, \frac ...
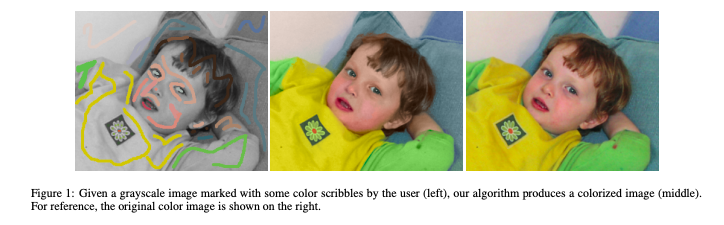
Colorization using Optimization
论文概述 [1]
在本文中,我们提出了一种简单的着色方法:基于一个简单前提:时空中具有相似强度(intensity:Y)的相邻像素应该具有相似的颜色。 我们使用次成本函数形式化这个前提,并获得一个可以使用标准技术有效解决的优化问题。
[1]Levin, Anat, Dani Lischinski, and Yair Weiss. “Colorization using optimization.” ACM SIGGRAPH 2004 Papers. 2004. 689-694.
目标函数Y可以通过gray图像作为已知信息,因此我们需要通过临近像素的推测U和VMINIMIZE
J(U) = \sum_r \left( U(r) - \sum_{s \in N(r)} w_{rs} U(s) \right)^2J(V) = \sum_r \left( V(r) - \sum_{s \in N(r)} w_{rs} V(s) \right)^2
r: 目标像素 N(r):临近像素
$w_{rs}$的条件
两像素间Y越相似,w越大;两像素间Y差值越大,w越小
和为1
约束条件相邻像素 ...