PCに複数のCUDA環境を作る
最近は仕事関係でtensorflowに触れ始めたが、色々慣れない操作やトラップがあって、まだ忘れていないうちに記録する
PCに複数のCUDA環境を作る
TFをインストールしようと思った時、なんと…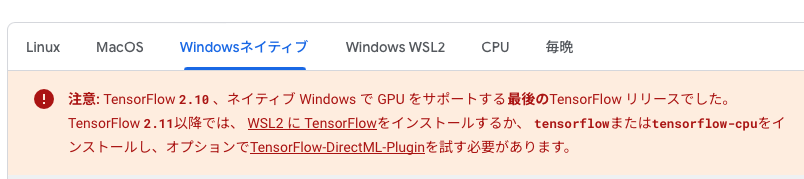
windows OSでTF-gpuをデプロイしたいならば、最高でも2.10しかない。もっと高いバージョンを使いたいならば、WSLのUBUTUNディストリビューションを使う他ない。(WSL2のブログまだ中途半端なのであまり自信ない・・・)
公開されているTFモデルでもこれから検証しようモデルでも、どちらでも結構古いモデルが多い気がする。だから古いTFでも対応できるはずかなという気持ちで、今度TF2.10.0のインストールを目指す。
GUDA要件確認
GPUに依存するライブラリをインストールする前に必ず確認するもの
- 対応するCUDAバージョン
- 対応するcudnnバージョン
- 他の依頼関係
必ずどこかにある。ホームページではパッとわかる場所ではないが、Googleすれば出る。tensorflowはソースからビルトでCUDAバージョン要件を見つけられる。
https://www.tensorflow.org/install/source?hl=ja#gpu
- cuda: 11.2
- cudnn: 8.1.0
現在のCUDAバージョンを確認する:nvcc -V
>>> 11.8
nvidia-smiで表示するバージョンはインストールされたドライバがサポート可能の最大バージョン
ちなみに、自分のPCにはすでにPyTorchが入っていて、サポート可能のCUDAは11.8以上だ・・・なので、複数のCUDA環境を作るしかない
CUDAのダウンロード
ダウンロード先:https://developer.nvidia.com/cuda-toolkit-archive
windows11の選択肢はないが、10で大丈夫らしい
インストラーは正常にダウンロードされたが、こういうエラーが出ました: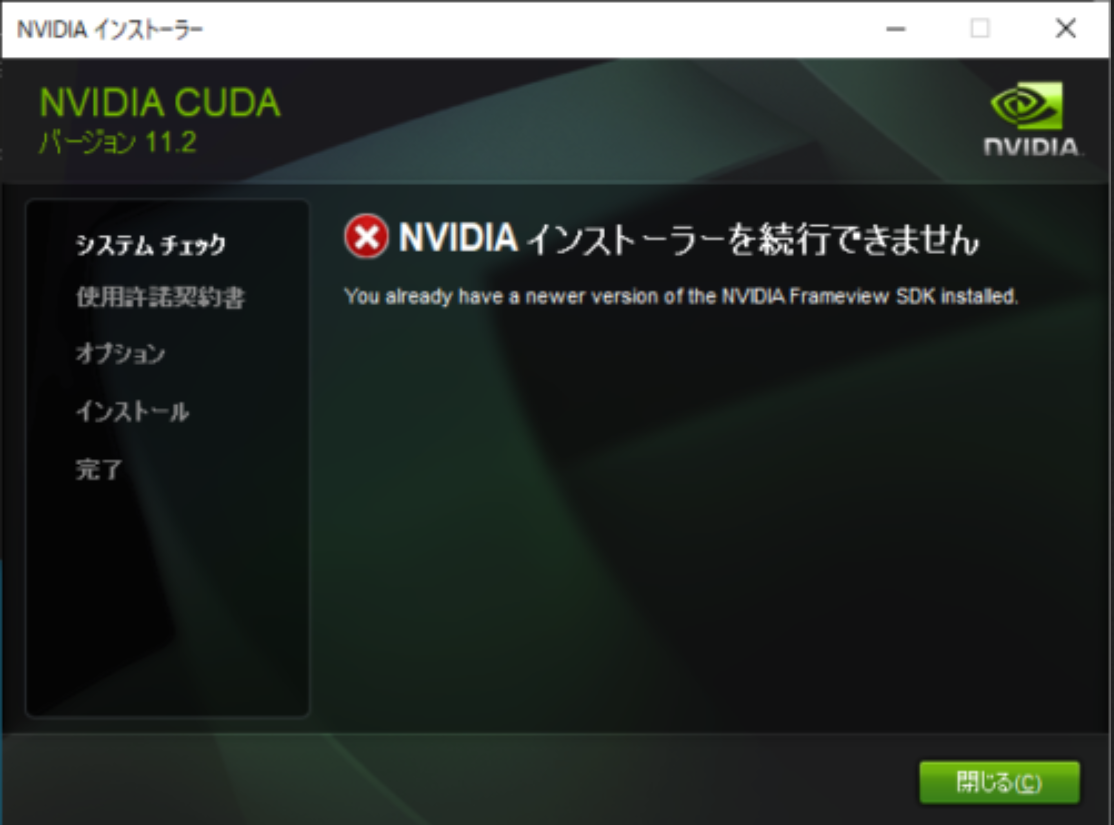
つまり、もっと高いバージョンがインストールされた状態ではこのエラーで、止められる。
色々調べたが、大体初めてcudaをインストールをする人と、再インストールする人です。解決方法はsdkファイルを削除することだ。
https://gugu-ran.hatenablog.com/entry/2023/06/28/010146
でも二個目をインストールする場合には、削除すると一個目に影響を与えないの?
という疑問を持ちつつ、deleteしてみた。さいわい、大丈夫だった。正常なインストール手続きに入った。
- システム > インストールしたアプリ > NVIDIA FrameView SDK
カスタムモードでインストールを進める。
optionの画面が出るはず。複数のcudaが欲しい場合に、特にすでにインストールされたcudaのバージョンが高い場合、比較的に新しいドライバーはもうインストールされている状態だ。ここでもし古いドライバーで上書きしたらエラーが出るかもしれない。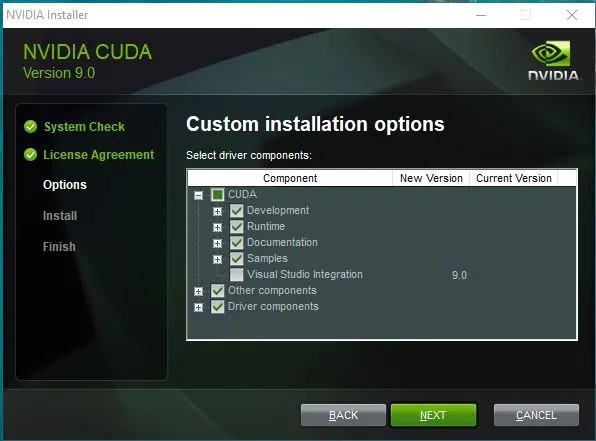
なので、ここはcudaだけをチェックを入れることにする。
できたら、一個目のcudaとおなじフォルダの下に11.2というフォルダが作成された。
PATHが通っているかどうかを確認
- システム > 詳細 > 環境変数 > システム環境変数
現在使うCUDAと関係ある変数は二つある
- Path:cudaのbinフォルダに指す
- CUDAPath:デフォルトのcuda
一応、11.2のパスは書かれているかどうかだけを確認
cudnnのダウンロード
だうんろーど先:https://developer.nvidia.com/cudnn-archive
cuDNN Library for Windows (x86) をクリック
ダウンロードされた圧縮ファイルを解凍して、中身を全部11.2/にコピー(管理者権限)
- bin
- lib
- なんだっけ
- わからないライセンスみたいのファイル
複数cuda間のスイッチ
先言ったシステム変数は、実はcudaの実行順位を決める
- Path:上にあるバージョンは先に実行される
- CUDAPath:デーフォルトで実行されるcudaバージョン
なので、Pathの中に、11.2を11.8より上に移動して、cudaPathも11.2に変更する。
ターミナルを再起動
nvcc -V
11.2が出たら成功した。
TFとPyTorchの比較
GPU実行の最適化方法は違う
- TFは全てのGPU容量をつかちゃう傾向がある。同じ規模のモデルで同じ操作を違う環境で実行させると、TFの環境では24555MB使う一方で、PyTorchでは877MBしか使わなかった
デフォルトのデバイスは違う
Pytorchでは以下のようなコードで指定しないと、デフォルトはCPUで実行するmodel.to("cuda:0")
image.to("cuda:0")
pred = mdoel(image)
でもTFの場合だと、なんと。。。model = keras.mdoels.load_mdoel("xxx.h5dl")
というような一行だけでいい。。。
もしcudaが存在する場合には、自動でGPUで実行される。存在しないとCPUで実行