【论文精读】Geolocation Estimation of Photos using a Hierarchical Model and Scene Classification
Eric Müller-Budack, Kader Pustu-Iren, Ralph Ewerth: “Geolocation Estimation of Photos using a Hierarchical Model and Scene Classification”. In: European Conference on Computer Vision (ECCV), Munich, Springer, 2018, 575-592.
Github: https://github.com/TIBHannover/GeoEstimation
作为毕设的重点参考文献,实在非常惭愧压根没有精读过。虽然其实有点本末倒置了,但至少为了论文的故事性,我还是得将这些文献一一读通。
尝试过很多读文献的方法:翻译,做笔记,逐字逐句。但是我发现这样的成效甚至远远没有我看别人的读后笔记收获多——目标太多太杂了。本次尝试使用新的方法:1. 先上网收集别人的笔记 2. 通过别人的笔记抓中重点,有针对性的看原文并生成自己的理解。
参考笔记1
https://blog.csdn.net/qq_42718887/article/details/111052027
背景
过去的Geo-localization的方法绝大多数都属于有约束的方法,除了PlaNet这类很少一部分论文将预测照片GPS坐标扩展到了全球范围,其他方法或多或少地限制了区域、影像资料或者地标建筑等等。
创新点
为了解决Geolocation Estimation的问题,引入了层次模型和场景分类。
- 层次模型: 利用多重精度网格切分将层次信息整合进Geolocation Estimation之中,以提升无限制方法的精度
- 场景分类:将场景分类信息整合进Geolocation Estimation之中,以提升无限制方法的精度
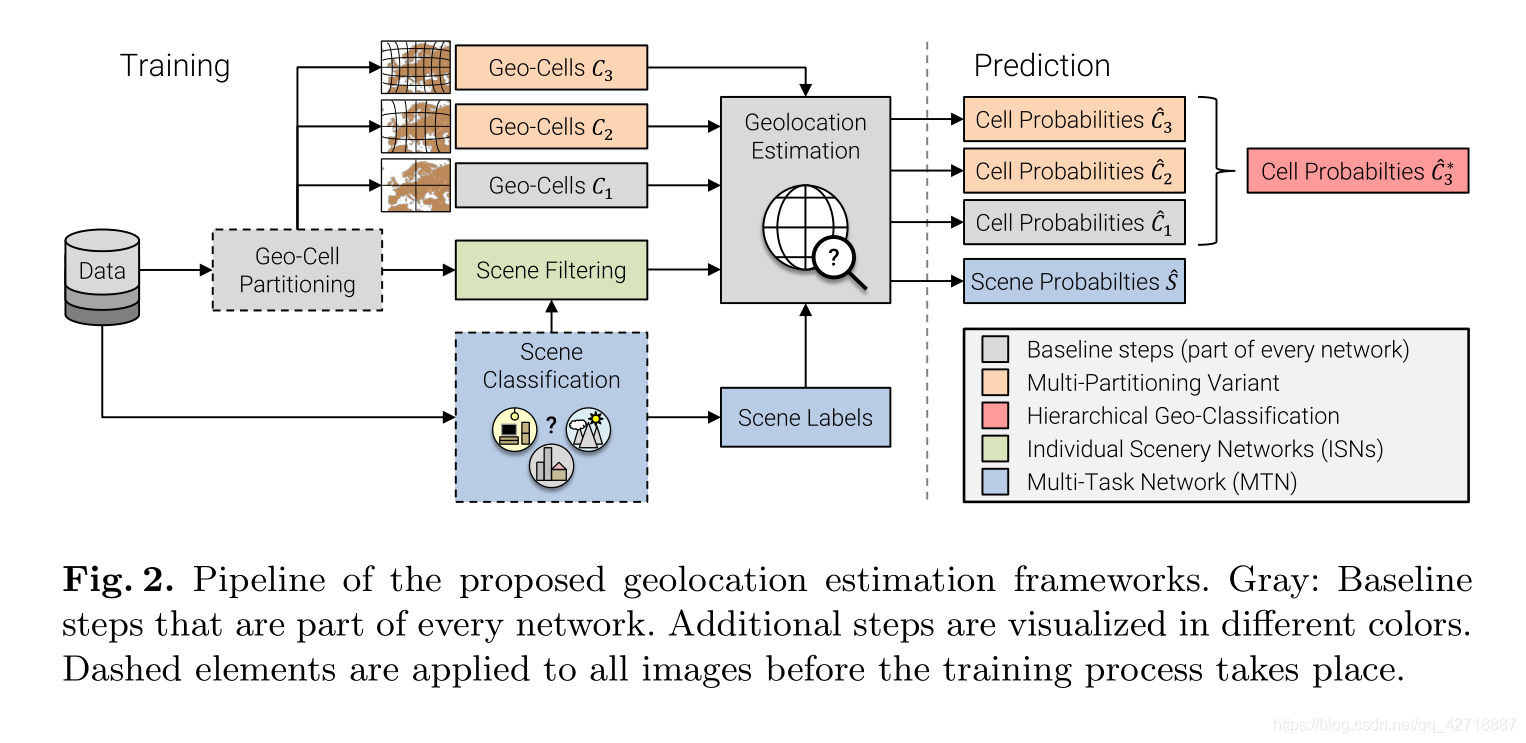
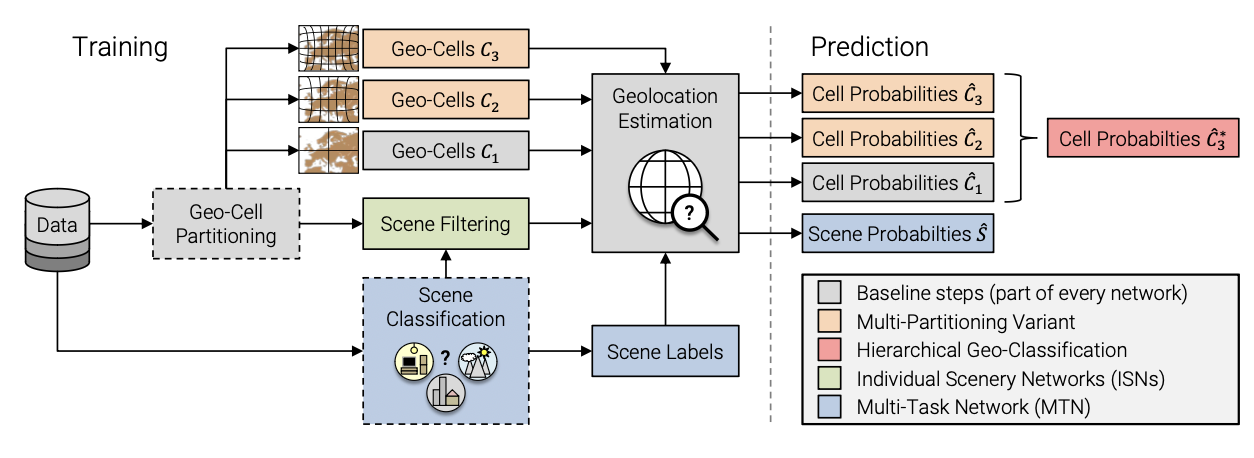
技术细节
场景分类模型:ResNet152
数据集:Places2, 365 classes, 16,000,000 pics
训练:将365个分类合并归纳后,按照种类分为16类,按照场景分为3类,分别进行训练
- S16分类器
- S3分类器:(indoor,nature,urban)
后续大部分实验都是基于S3
推理:使用训练好的S3分类器对训练集预测标签
实验:现在作者有了一堆带有场景标签的数据集图片,为了利用这些场景信息,作者提出了两种网络结构
- ISNs(Individual Scene Networks):针对这不同场景标签单独训练复数个网络去预测图片坐标
- MTN(Multi-Task Network):多任务网络,即在预测坐标的同时预测场景信息,损失函数由场景预测损失和坐标预测损失共同组成
后续实验证明了MTN没啥用,ISNs效果好一点。
层次模型由Geo三组不同精度的划分组成的,c1,c2,c3,精度越来越细。
划分的时候保证了每一层的每一个geo-cell在上一层至多有一个更粗精度的geo-cell与其对应。类似于构造了一个树状的结构,一个节点至多有一个父节点。然后,借鉴YOLO9000用树状的softmax去预测该图片落入每一个geo-cell的概率。
结论
这篇论文和PlaNet一样都是讲Geolocation Estimation转化为网格分类问题。这篇论文启示我们,在面对无约束问题的时候,多想想引入层次信息(从某种意义上来说,这篇论文引入的场景分类也能算一种层次信息)以划分研究的范围,在每个小范围再利用模型解决问题,从而达到减少研究现象的异质性,提高精度的目的。
参考笔记2
为什么需要场景分类
- 地理定位有很多限制因素,比如不同的角度,白天的时间,摄像机时间,所以很多的算法都关注的城市图片
- 城市的场景更多的靠建筑、人类和街道、汽车等区分
- 森林等自然的场景主要靠动植物
- 室内场景主要靠室内陈设
因此提出可以对不同的类型的地理位置(室内、自然环境、城市等),单独训练预测器
Baseline system
在Resnet上添加一个全连接层: 不依赖于不同环境和不同空间分辨率的信息
笔记正篇
Q&A
训练集究竟用的是什么?Im2gps?
不同模型使用了不同的训练集。
是否有提供已划分好的places2
提供了。并提供了根据自己的数据集生成cell2的代码。
MTN是指根据不同分类希望获得不同权重的同时预测方法吗?
并没有显性表达是哪种解决方案。但是根据loss是加和算出来的推测的话,应该是下面的方法2。
关于Multi-mask
两种实现方式:- ネットワークの最終層で複数タスクの結果を同時に出力する方法
- ネットワークを途中で分岐させて各タスクの結果を出力する方法
实现1: https://colab.research.google.com/github/machine-perception-robotics-group/MPRGDeepLearningLectureNotebook/blob/master/11_cnn_pytorch/09_multitask_fundamental.ipynb#scrollTo=kIZfJ4frt1yt
输出层的节点数=任务数:出力ユニットは,0-1番目が鼻の座標 (x, y) ,2-3番目が性別 (male, female) に対応します.
实现2:https://colab.research.google.com/github/machine-perception-robotics-group/MPRGDeepLearningLectureNotebook/blob/master/11_cnn_pytorch/10_multitask_applied_mtdssd.ipynb#scrollTo=jmI9DjEpzE4y
完成共通的特征提取后进入不同的CNN模块。最后分别生成两个task的预测结果。
借鉴YOLO9000用树状的softmax是什么
好像不是特别重要。还没看。
最终的loss权重怎么确定的?
每个实验模型的不尽相同,但并没有特地设定不同的权重,都是最简单的cross-entropy,平均或加和
预测S3的模型是否有提供?
官方只提供了使用多精度层次的baseline,因此本身就不包含场景分类器。
层次模型
基本参考PlaNet。
PlaNet粗读
基本数据
模型:Inception
数据集:Flicker扒来的,im2gps
主要贡献
- 不同于过去的retrievel方法,将geo-localization问题转化为classification
- 生成每个分类项的输出
- 通过softmax预测最大可能的分类项
如何均匀的分割网络 → Adaptive partitioning using S2 Cells:利用了谷歌的s2-geometry-library剖分地球网格
Adaptive partitioning using S2 Cells(S2 Cellsに基づいた地球分割)
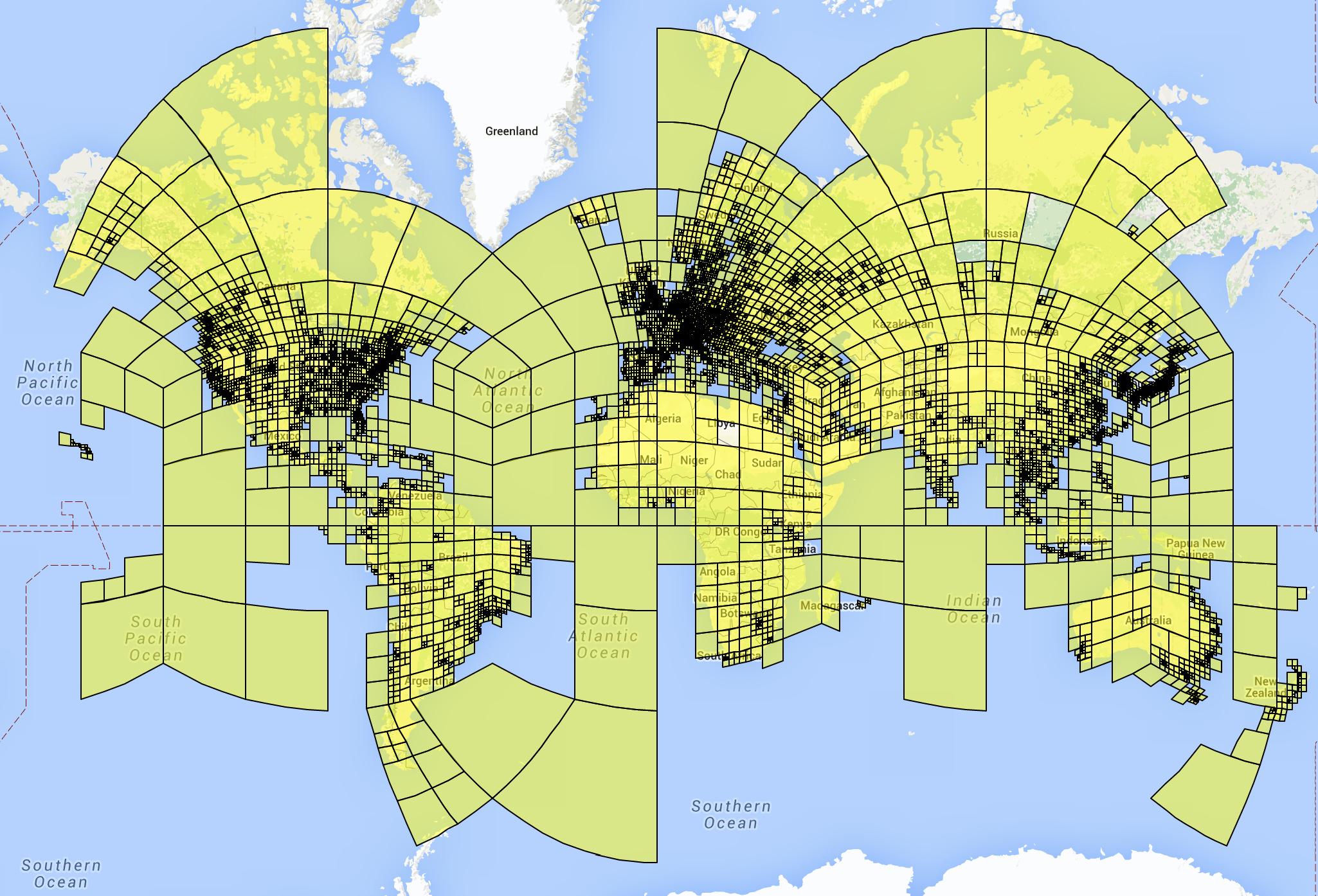
26,000cells, cost 2.5 months on 200 CPUs, train on 126M pics with Exif info.
- 利用s2 cells进行分割生成树状节点:
- 训练时将该图片的真节点设为1其他为0
- 当节点包含的图片数达到上限时就会再次切割生成子节点
- 当节点包含的图片少于下限时就会丢掉,因为这里大多是海洋天空等难以定位的
模型
Baseline
利用预训练的resnet152提取器和生成的单一S2信息进行训练。
网络结构:resnet152的global pooling层上添加了一个具有|C|个节点的全连接层,以此训练resnet152将不同图片分类到不同cell的能力。
损失函数:使用one-hot。正确的cell为1错误的为0。计算cross-entropy。
Multi-Partitioning Variant
多重精度的层次模型。不同于PlaNet使用单一的S2结果,本文使用三层精度。
网络结构:resnet152的global pooling层上添加了一个具有|C1|+|C2|+|C3|个节点的全连接层,以此训练resnet152将不同图片分类到不同且多精度cell的能力。
损失函数:每个精度依旧是one-hot。再将三个精度的损失做平均。
Individual Scene Networks (ISNs)
根据不同场景分开训练特征提取器。
网络结构:原始baseline只需要一个network完成所有的分类。而ISNs的想法是先用场景分类器特定图片的场景,再用对应的特征提取器预测。缺点是场景越多需要预训练的特征提取器越多。
Multi-Task Network (MTN)
同时预测场景和cell。
网络结构:将resnet再多分出来一个全连接层,以预测场景。最终的损失由场景损失和cell损失之和组成。
训练
场景分类器:在Places2上预训练的分类器+S3的微调
特征提取器:在imagenet上预训练的分类器+YFCC100M(5,000,000)的微调
测试:im2gps+im2gpsTEST
- 因为im2gps的图片里大多不包含landmark(5%)
结果
- 多精度层次模型的能力非常强,在baseline上也很明显
- 在多精度层次模型的前提下,ISNs优于baseline
- 多任务模型MTN完全不行
- 作者认为多任务模型带来的复杂的基层特征不适用于位置预测任务
评价手法
- 针对分类模型进行了TOP评价
- 针对预测模型进行了准确度评价以及分区域占比的评价
总结和学习
baseline可以使用已经预训练的,现存于网路上的模型,然后表达如何在此基础上进行更改
对我来说,我可以将基于位置特征的图像模糊的作为baseline
在此基础上,我可以尝试1. 基于位置特征的inpainting 2. 基于位置特征和classGrad的inpainting 3. 优化mask的大小cell结构对位置预测的有效性
借此生成完全不同的class的图片,实现位置偏移
场景分类器的有效性
可以作为class-condition优化生成图片的主观质量:但是也要考虑inpainting本身就已经学习了