Lora学習による画風生成
https://github.com/kohya-ss/sd-scripts
を利用してLoraによる学習方法と
https://github.com/AUTOMATIC1111/stable-diffusion-webui
でLoraモデルによる色々試した結果
利用するソースコードの準備
git clone https://github.com/kohya-ss/sd-scripts.git
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
データ準備
タグ学習方式を利用します。
画像のタグを学習させることで特徴を生成できるようになる。
何らかのツールでタグを自動で生成させる
e.g. wd14taggerによるタグ付け
$ cd sd-scripts/finetune
$ python tag_images_by_wd14_tagger.py --batch_size <batchSize> <pathToDataDir>すべてのキャップションを一つのファイルにまとめる(メタデータファイル)
python merge_dd_tags_to_metadata.py --caption_extension .txt <pathToDataDir> meta_tag.json画風を表示するタグを加える
たとえばモネの画風を学習させようとしたら、“mone”というタグをプラス
## before
<caption>: {
"tags" : "1girl, long_hair, looking_at_viewer, blush, smile"
}
## after
<caption>: {
"tags" : "mone, 1girl, long_hair, looking_at_viewer, blush, smile"
}これで自動でモデルはmonaをモネ画風と関連づける
例外処理
透明背景
- rgbaタイプ:shape = (w,h,c=4)
- a=0 ↔ 完全透明 a=255 ↔ 完全可視
透明部分を白い背景で埋めしておく必要がある
透明があるの画像をそのままモデルに学習させるとrgbとして処理され、黒いと認識される恐れ

失敗例
Lora学習
概要
論文:LoRA: Low-Rank Adaptation of Large Language Models
LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency.
LLMのFinetuning方式の一種
- 軽量モデル
- 計算早い
- low-specのパソコンでもOK
手順
ベースモデルのダウンロード
huggingFaceでは色々なdiffuserモデルが提供される
学習スクリプトをGPU環境で動かす
https://github.com/kohya-ss/sd-scripts/blob/main/docs/train_network_README-ja.md
## 簡単実行例
accelerate launch --num_cpu_threads_per_process 1 train_network.py
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
--in_json=<tag_path>
--output_dir=<学習したモデルの出力先フォルダ>
--output_name=<学習したモデル出力時のファイル名>
--save_model_as=safetensors
--max_train_steps=400
--learning_rate=1e-4
--xformers
--mixed_precision="fp16"
--network_module=networks.lora- Lora学習率は一般1e-4~1e-3
- stepSize = 500*画像枚数は良さそう(個人的な経験)
Hyper-parameterの設定についての参考:
モデルの出力を待つ
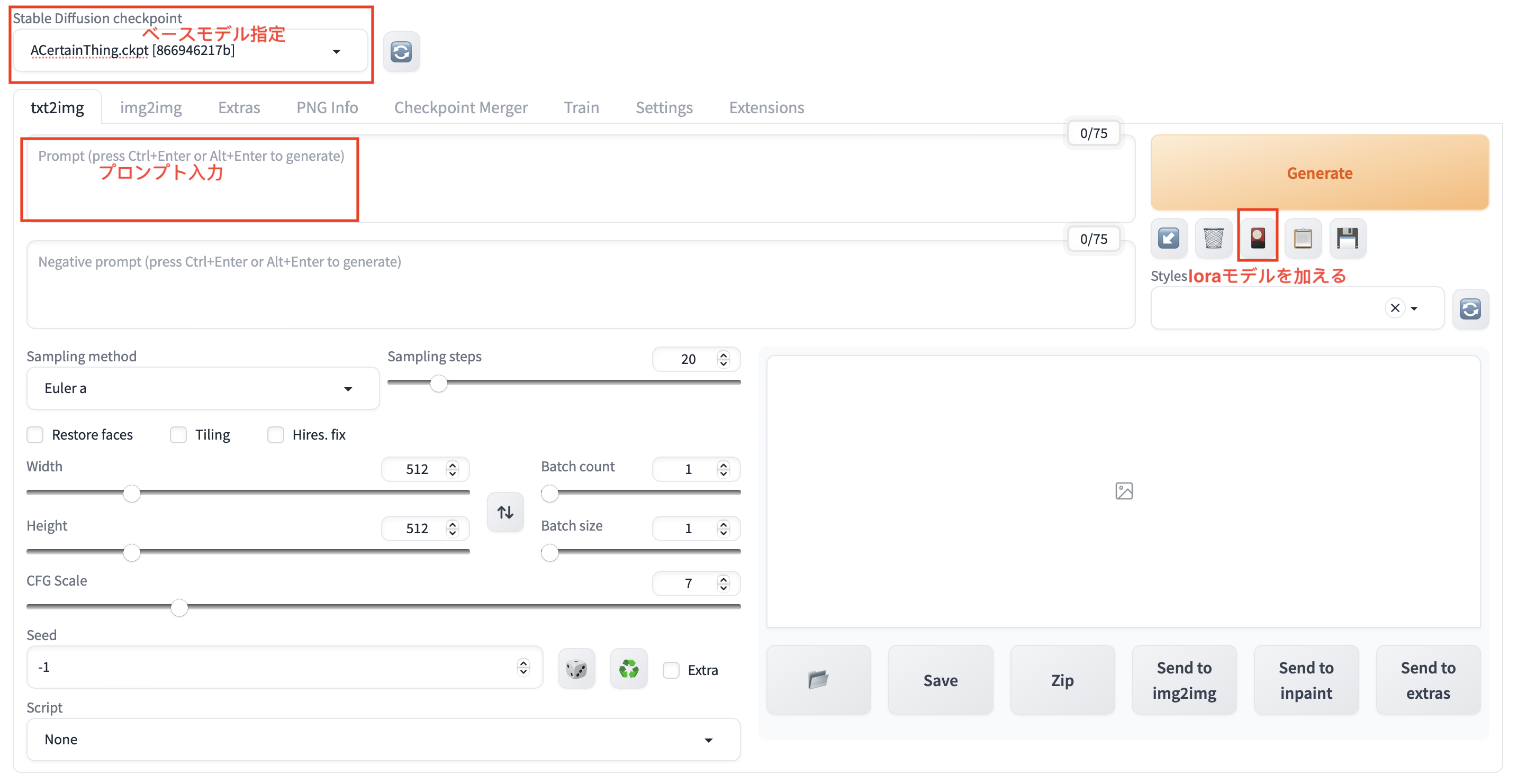
stable-diffusion-webUI
めんどくさいdiffusionをUI化してインタラクティブ操作可能になる。
コマンドラインによる推論も可能ですが、UIの方がわかりやすくて色々な機能も完備する。
ベースモデルをフォルダ
stable-diffusion-webui/models/Stable-diffusionに移動Loraモデルをフォルダ
stable-diffusion-webui/models/Loraに移動run
./webui.sh:バーチャル環境の作成と依存ライブラリのダウンロード
さっき学習した画風で好きな画像を生成できた!
ControlNet
写真アプリではAIイラストレターの機能がよく見られる
人の姿勢が保持するままに他の画風でイラスト化機能だ

ControlNetは画像を参照元としてポーズを固定することができます
ControlNetをWebUIに導入する:
https://koneko3.com/how-to-use-controlnet/
異なるLoraモデルで同じポーズを生成した結果:

memo
- ControlNetには色々な種類があって、得意な生成分野も違います
- ControlNetを重視するかpromptを重視するかを調整するweightも結構重要だ