【花书】从函数梯度到深度学习的优化算法
参考深度学习花书
第四章 数值计算【梯度下降,约束优化】
第八章 深度学习中的优化【优化问题,优化算法】
主要整理了1. 梯度的定义和性质,以及如何运用到寻找函数的极值点 2. 寻找极值点中,如果我们需要添加额外条件,需要使用到约束优化 3. 深度网络的优化学习中的挑战和应用 4. 基于梯度,当今流行的深度网络优化算法
梯度
梯度定义
梯度不仅可以表现为一个函数 $y=f(x)$,他的定义式还可以解读为“表明如何缩放输入的小变化才能在输出获得相应的变化”:
因此梯度对我们的优化问题非常有用:她告诉我们如何通过更改x来略微的调整y → 梯度下降法
一次梯度
当我们有多个输入(一个函数多个变量)时,梯度是元素为 $\frac{\partial}{\partial x_i}f(x)$ 的向量
当我们有多个输入和多个输出 (多个函数多个变量)时
Jacobian 矩阵:相比于只有多个输入的情况,我们将同一个输出函数对于不同的变量的偏导写到行上,不同输出函数写到列上;因此构成了矩阵
二次梯度
- Hessian 矩阵
梯度性质
一次梯度
明显的是,大于0函数递增,小于0函数递减。但我们无法确认当等于0时(临界点)函数的情况,因为他可能有以下任意情形:
- 局部极大点
- 局部极小点
- 鞍点
二次梯度
与曲率相关:小于0时为凸,大于0为凹
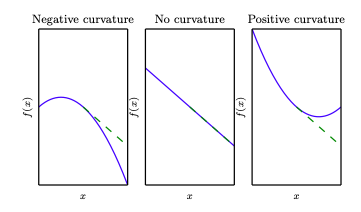
一次梯度与二次梯度的结合
方法一:
$\nabla f(x) = 0, \nabla^2 f(x) > 0$ :极小值
$\nabla f(x) = 0, \nabla^2 f(x) < 0$ :极大值
方法二:
实际上,当一阶前提符合时(为0),我们并不需要计算出所有输入的二阶;而是利用hessian矩阵的实对称性即特征值分解,判断大于0还是小于0。具体方法是计算hessian的正定性(所有特征值均为正),则H大于0。其他情况
- 均为负,H小于0
- 有正有负,鞍点
利用梯度的优化算法
梯度下降
梯度下降是只利用一次梯度的一种最简单的优化算法。
由梯度性质可知 $-sign(f’(x))$ 永远指向y减小的方向(1或-1),因此我们据此对x进行更新(如果是多维输入则是偏导且对每个x元素更新):
$\epsilon$ 是学习率,也就是要基于减少方向缩放多少作为我们的步长
牛顿法
牛顿法是结合了一次梯度和二次梯度的优化算法。
当f为正定二次函数时,牛顿法可使它直接跳至全局最小点
约束优化
大多数情况,对于x所有可能值最小化函数并不是我们所期望的。我们往往会“有条件的”进行优化。数学方式来说,也就是希望在x的某些集合S中找f(x)的最大值或者最小值。这称为约束优化。集合S内的点称为可行点。
KKT方法
集合S的描述:
我们通过等式和不等式的形式描述S。我们使用m个等式约束( $g^{(i)}$)和n个不等式约束( $h^{(j)}$),则:
最小化问题:
实例:线性最小二乘
无约束的优化目标:
梯度下降法:
计算梯度:
$\nabla_xf(x)=A^T(Ax-b)$
更新x
$x \leftarrow x-\epsilon A^T(Ax-b)$
有约束的优化目标(约束:范数小于1)
计算梯度
$\nabla_xL=A^T(Ax-b) + 2\lambda x$
$\nabla_\lambda L=x^Tx-1$
联合求解
优化目标
深度网络的优化方法:寻扎神经网络上的一组参数 $\theta$,它能显著的降低代价函数 $J(\theta)$,该代价函数通常包括整个训练集上的性能评估和额外的正则化项
对于代价函数,我们实际上是希望能够对数据的原始分布进行最优化,即:
但实际上我们不能获得所有的数据,即不能得到真实的原始分布。因此我们另辟蹊径,假定训练集的采样代表了原始数据的分布,称为“经验”
基于最小化这种平均训练误差的训练过程称为经验风险最小化。但其难点是如果使用高容量的模型会简单地记住训练集,导致过拟合。
采样方法
- 使用整个训练集进行优化的算法称为批量算法
- 每次只是使用一个样本的称为在线算法
只使用一部分样本的称为小批量方法,或随机方法
如何确定小批量的大小
- 随着批量的增大,预测的梯度精确性理所当然的会上升,但其回报是小于线性的
- 当批量小于某个值时将无法使用多核架构,计算时间也不会下降
- 硬件设施的计算能力
- 使用GPU时,2的幂数的批量大小会获得更小的运算时间,一般使用32~256
- 批量越小,噪声越大,则带来越大的正则化效果(泛化能力)
- 由于梯度的高方差,我们需要设置更小的学习率来保持稳定性。但是越小的学习率也会带来更久的运行时间。
神经网络优化的挑战
病态
最具代表性的是二阶导Hessian矩阵的病态。效果是尽管梯度很强,学习会变得非常缓慢
局部极小值
鞍点
多类函数有此性质:低维空间中大多数为局部极小值;但在高维空间中,鞍点更为常见。这使我们更难找到极值点。尤其对于牛顿法而言,它旨在找到最近的下坡,而并不是真的跳到极值点;因此除非最近的梯度为0的点是极值点,否则牛顿点会更容易跳到鞍点处。这也说明了为什么在高维空间中,二阶方法并不能取代原始的梯度下降法。
梯度爆炸
多层神经网络中通常存在像悬崖一样的斜率较大的区域。由于梯度的迅速增大,被更新的x值会被弹射到非常远的位置,使得我们错过了可能存在的极值点。
优化算法
参数初始化策略
标准初始化:从下列分布中采样权重
基本算法
SGD:随机梯度下降

在实践中,学习率 $\epsilon$需要随着回合数进行减低。在小批量算法中,采样带来的噪声并不会在达到极值点处消失,而是使代价函数趋于平缓。为了接近极值点,我们必须减少学习率避免产生震荡。
缺点:学习过程很慢
使用动量的随机梯度下降
加入了历史梯度对现在的影响。

$\alpha$越大,历史梯度对现在的影响越大。步长不再仅仅取决于当前的梯度,更取决于梯度的排列和大小:当许多连续的梯度指向相同的方向时,步长最大。
自适应学习率算法
AdaGrad
利用历史梯度的平方根的反比决定每个参数的学习率。在参数空间更为平缓的倾斜方向会取得更大的进步。

优点:加快收敛速度
缺点:从训练开始时就积累平方梯度的话会导致学习率过早和过量的减小
RMSProp
使用指数衰减平均以丢弃遥远过去的历史梯度

Adam
加入了偏置修正,修正一阶矩估计和二阶矩估计

常见算法总结
- SGD为随机梯度下降,每一次迭代计算数据集的mini-batch的梯度,然后对参数进行更新
- Momentum前几次的梯度也会参与到当前的计算中
- Adagard在训练的过程中可以自动变更学习的速率,设置一个全局的学习率,而实际的学习率与以往的参数模和的开方成反比。
- Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,在经过偏置的校正后,每一次迭代后的学习率都有个确定的范围,使得参数较为平稳。
一些经验谈
为什么我们依旧倾向于使用SGD?
尽管自适应梯度算法的收敛速度更快,但其泛化性能却比SGD算法差。具体来说,自适应梯度算法在训练阶段的进展很快,但在测试数据上的表现很快就会停滞不前。但是SGD通常对模型性能的改善很慢,但可以获得更高的测试性能。对于这种泛化差距的一种经验解释是,自适应梯度算法倾向于收敛到尖锐的极小值,其局部地区的曲率较大,所以泛化性能较差,而SGD则倾向于寻找平坦的极小值,因此泛化较好。[1]
参考资料
[1]为什么Adam 不是默认的优化算法?, https://zhuanlan.zhihu.com/p/557605698