【强化学习】chatGPT的工作原理
内容参考:
[1] How ChatGPT actually works : https://www.assemblyai.com/blog/how-chatgpt-actually-works/?continueFlag=49271bb2584143248da2304817eb2d87
[2] 强化学习一基础部分 : https://zhuanlan.zhihu.com/p/555303537
术语说明
- Capability(能力)
- Allignment(对齐性/泛化性)
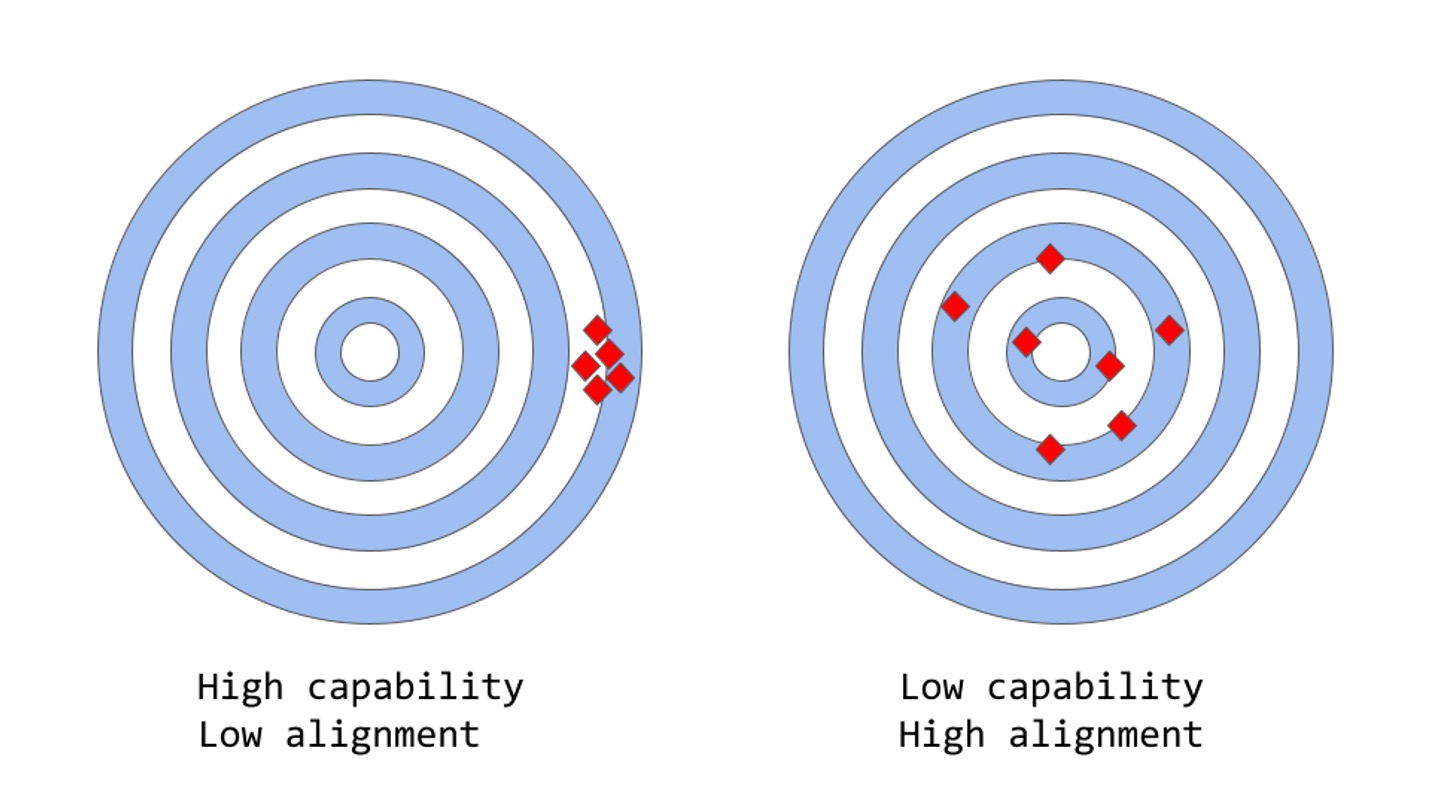
传统语言模型的缺陷
现在流行的语言模型训练方式有Next-token-prediction (下文预测)和 masked-language-modeling (遮挡预测), 如大名鼎鼎的transformer。这种方式使得模型能够学习完美构成的语句,却无法真正理解更高级别的语义内容。其特点是能力高,泛化度低。比起人类的复杂的判断系统(语境,常识等),语言模型更多而仅仅依靠上下文的出现概率(likelihood)进行判断。常见的缺点有:
- 缺少帮助性:无法遵循人类的指引(Instroduction)
- 捏造性:错误信息
- 缺少解释性:难以解释如何获得当前结果的
- 有毒性:有害信息
ChatGPT and RLHF
为了解决上述的问题,chatGPT基于GPT-3的模型 [3],加入强化学习方法,首次使用了Reinforcement Learning from Human Feedback [4]。
STEP 1. Supervised fine-tuning(SFT)
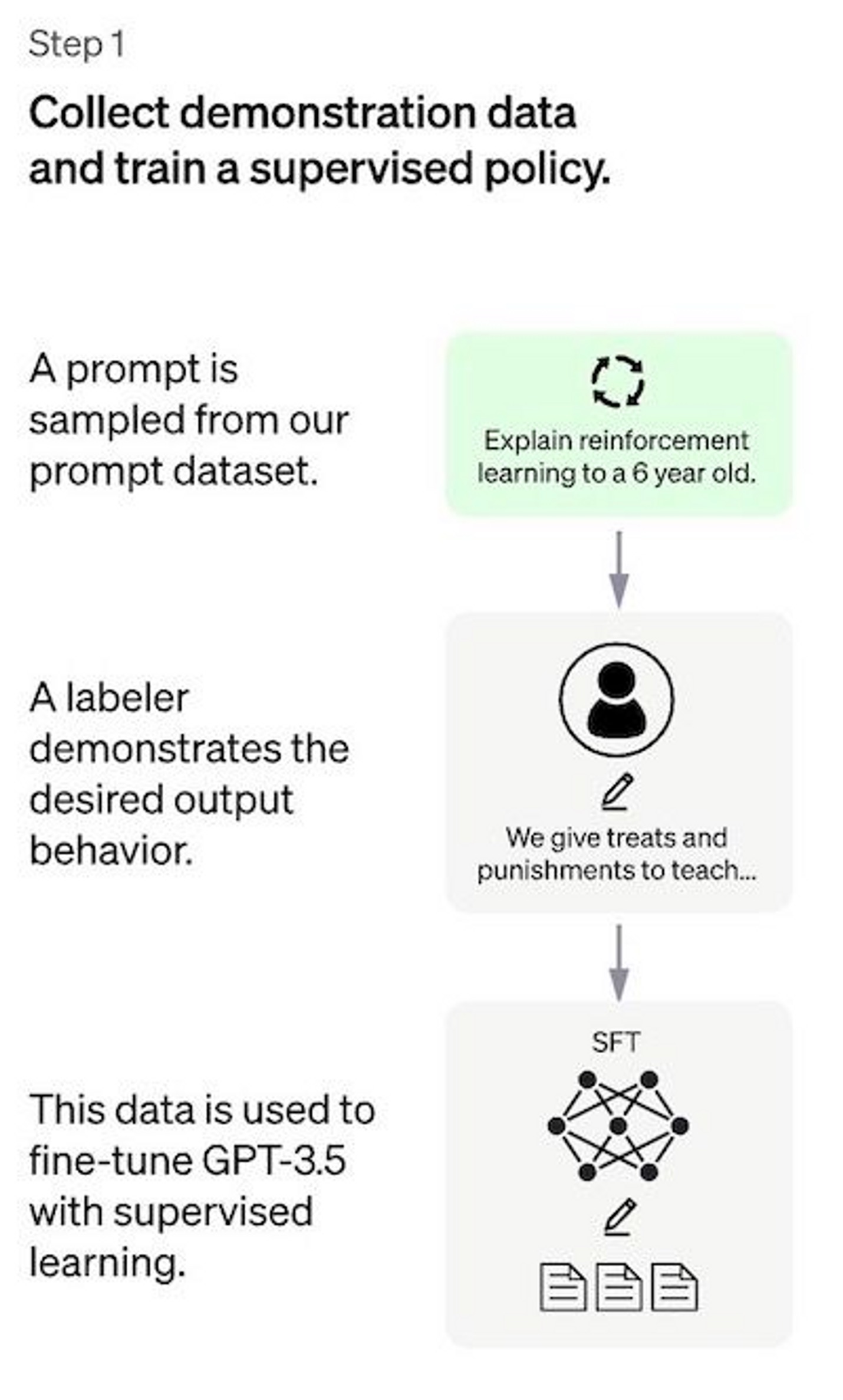
模型准备阶段。openAI选择了对已有的模型GPT-3.5进行fine-tune的方式而不是重头训练新模型。微调时使用了人工选择及编写的Prompt(指令)和Output(输出)组,对模型进行有监督的训练。
此步骤旨在使用精确而较小的数据集对已有模型针对我们想要执行的任务进行初步的训练,为之后真正的半监督优化做基础。有监督的数据集当然越大越好,但毕竟我们没有那么多时间和精力收集过于庞大的人工数据。
STEP 2. Rewrad moel(RM)
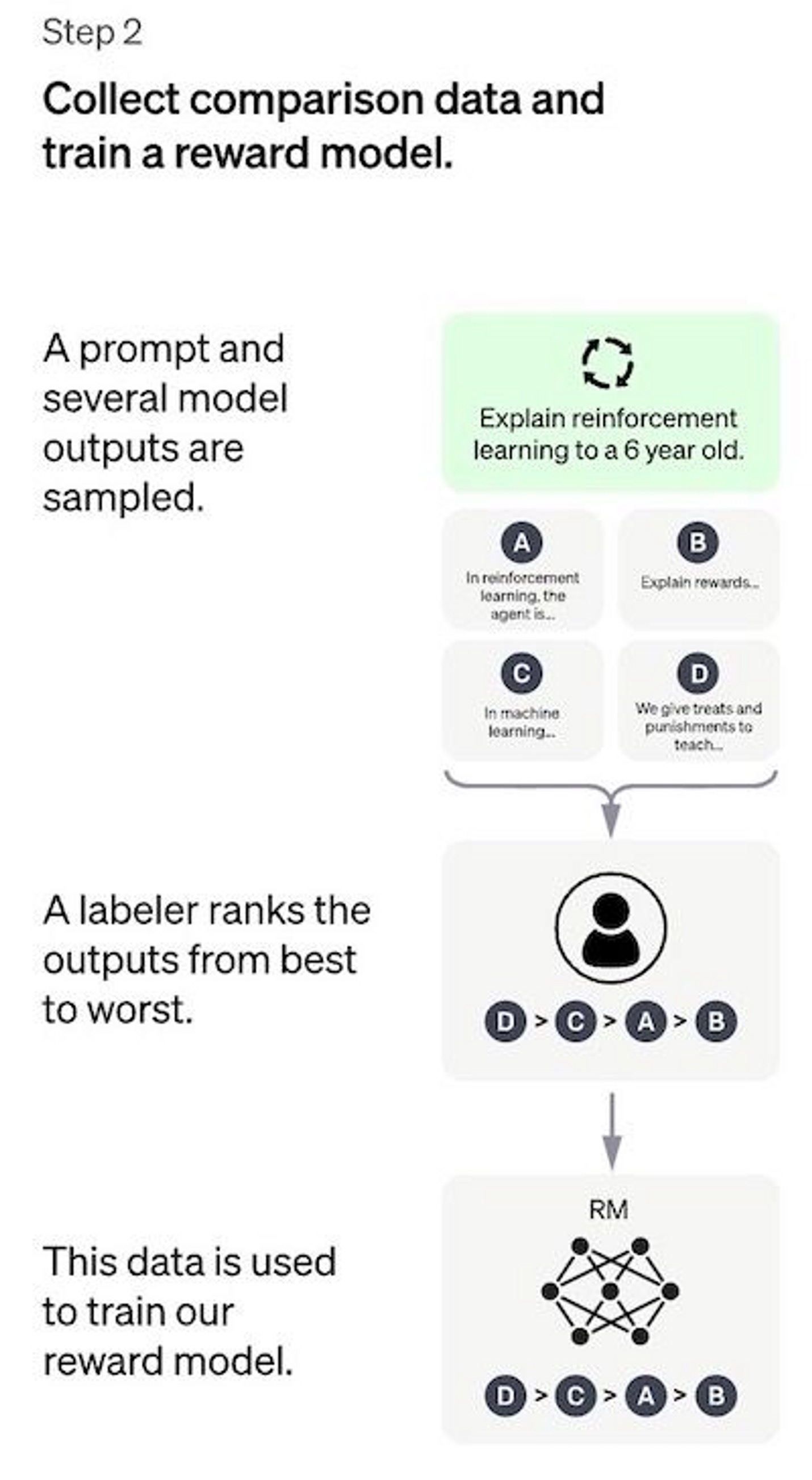
训练奖励模型,我更倾向于理解为评价模型。我们希望能有一个评价方式直接反馈给原模型(策略),而不是需要学习一个值(值函数)。具体方式是让模型对一个prompt输出多个结果,人类通过人工标记的方式对这些结果进行由好到坏的排序。这样,奖励模型习得了基于人类喜好的排序能力。
比起第一步的需要人工从头编写正确答案,此步骤的标记方式显然更轻松和迅速。
STEP 3. Proximal Policy Optimization (PPO)
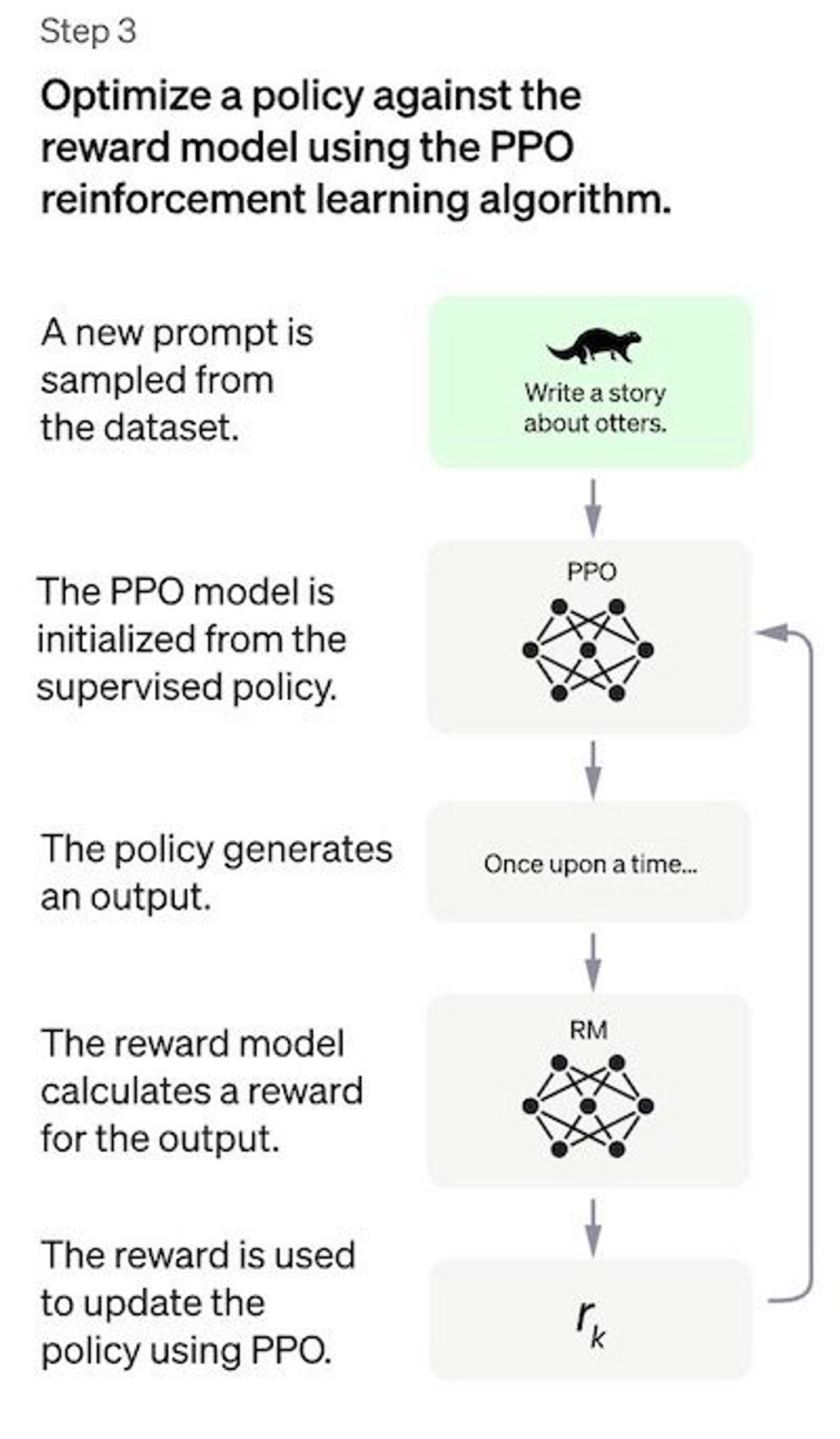
强化学习中常见的PPO(近端策略优化)。前文提到的策略由于粒度过大(优化方向不够明确),因此为保证基于奖励模型的排序结果的优化方向不至于过于偏离现实,要求生成的新策略要与在第一步训练的SFT的输出(旧策略)的差值不得过大(KL散度)。
每一个回合(iteration)一般包含复数个步骤,以保证策略的更新具有一定的远见性,而不仅仅是看眼下的利益。但是对于上一段落的KL散度的惩罚会在每一步中迅速执行,以保证回合内的策略的可信度。
评价方式
- 有用性
- 可信度
- 有毒性
局限性
由于多处使用了人工标注,再加上人工调参的过程,几乎每一步都会加入主观的数据偏差。这是该模型的本质局限性。(成也萧何,败也萧何)
其他的问题:
- 缺少控制实验:RLHF在这里面究竟起到了多大作用?
- 对比数据中缺少真实标注:对比数据即第二步中生成的多个结果。即使里面有的结果非常离谱,人工也只能进行“排序”而无法“告知”,即没有告诉其“应该怎么做”。这导致对比数据的偏差极大。
- 人类的喜好并不一致。
- RM模型对歧义句或同义句的理解程度
- 富含经验的模型:有时模型会抓到奖励模型的一些“暗门”,据此获得高额奖励。
参考资料
[3] “Training language models to follow instructions with human feedback”, arXiv:2203.02155 (2022)
[4] 拆解追溯 GPT-3.5 各项能力的起源 : https://www.notion.so/360081d91ec245f29029d37b54573756