闲看-数据集会有刻板印象吗?
本来是想看Ruth Fong这位作者的一些关于可解释模型的一些论文,但是无意中看到她作为共作的讨论数据集的性别刻板印象的论文,沉迷于此看了一天倒是忘记了最开始是要看别的来着…
Meister, Nicole, et al. “Gender Artifacts in Visual Datasets.” arXiv preprint arXiv:2206.09191 (2022).
标题:Gender Artifacts in Visual Datasets
论文地址:https://arxiv.org/abs/2206.09191
关键词:AI fairness, gender bias, dataset analysis
0. 摘要
我们已经知道性别偏差会出现在大型图像集中并且会影响下游任务模型。许多前序工作已经提出弱化这种偏差影响的手法比如尝试将性别情感相关的情报从图片里删除。为了理解这些手法的可行性和使用性,我们调查了大型图片集中究竟有哪些性别伪影(gender artifacts)。我们定义,性别伪影应该是一个
- 可视的并且会被现代模型学习到的
- 能以人类思维解释的
与性别相关的线索。通过我们的分析,我们发现在COCO和OpenImages数据集中,伪影可以说是无处不在,下到低阶信息(如色彩信息),上至高阶信息(如姿势和位置),都存在性别伪影。因此我们认为通过删除伪影的方法是不可行的。并且我们认为作为研究员和训练者的责任,他们更应该注意数据里的性别分布,并应该加强手法对这些分布偏差的鲁棒性。
1. 介绍
我们现在已知了很多深度学习模型的衍生物都有社会偏差。一种主要的假设是这种偏差源自于输入数据本身的问题。许多偏差都来自于特定群体的相关数据的缺乏,如天然的性别分布已经被论证不足以缓解模型的偏差。因此许多手法提出将具有性别色彩的元素进行遮挡的方法以避免输入数据的不均匀。
在本文中,我们不仅关注这些数据集的偏差,并且探索了这些性别信息究竟多大程度能被除掉。因此首先我们定义了性别伪影应该是可学习的和可解释的。并且为了探索这些伪影,我们生成和对比了许多不同版本的数据(如灰度化的图片,被遮挡背景的图片等),以探索它们的性别预测程度。
但是我们并不赞成任何预测性别的行为。并认为这里并没有任何理由足以支持这一行为。
根据上述工作,我们最终发现在COCO和OpenImage里性别伪影无处不在。如下图中仅仅是计算了图片中三原色的平均值,就能够看出两性之间的明显差异。通过平均值模型预测度为,COCO:58.0%, OpenImages:59.1%
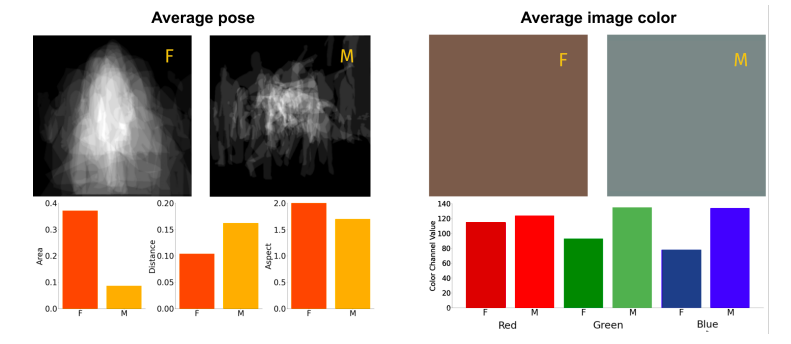
这些发现的暗示如下:
- 性别伪影存在于图片的每个角落,因此过去的删除特定性别伪影的手法也许是无效的。我们更推荐研究者使用注重公平的模型,以及非聚合的验证矩阵。这能帮助发现潜在的群体偏差。
- 在我们的发现中,这些性格偏差的无处不在性导致最终的预测可能是毫无道理的。比如每当让模型预测性别时,我们需要积极地考虑预预测依据是什么;模型是真的学习到了有意义的理由,还是仅仅是因为图片更红一些。
最后,我们也要考虑不是所有伪影都是错误的。有一些也许是真的能够帮助我们区别两个群体,它们是重要的特征;但有一些仅仅是讨厌的刻板印象。我们需要考虑哪些是要避免的。
2. 相关工作
3. 实验
3.1 数据集
使用COCO和OpenImages的主要原因是它们是少见的能直接获得性别标签的注释。
3.2 模型参数
3.3 道德考虑
以下开始是产生性别伪影的原因的实验和探讨
4. 分辨率和颜色
我们测试了测试集在112x112, 56x56, 28x28, 14x14, 7x7这几种分辨率情况下的预测情况。随着分辨率下降,准确度也逐步下降,但是颜色也逐渐变得单一。因此我们也考虑了当转化为灰度图片后随着分辨率下降预测度的情况。结果如下图所示。
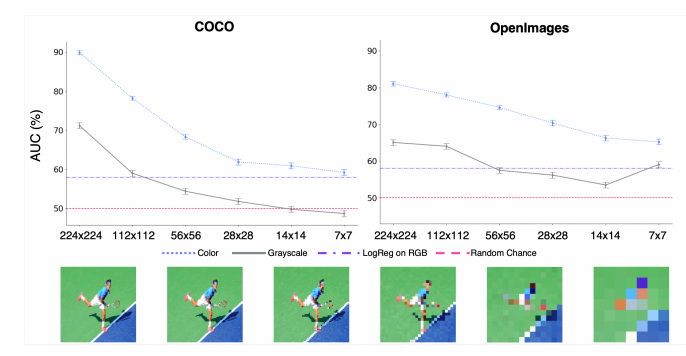
在28x28的分辨率下的COCO数据集中,彩色图片预测率有61.9%而灰度图片仅有51.9%。这说明在图片的物体形状不再具有意义时,性别伪影很可能来自于色彩的影响。
并且即使将分辨率低到了7x7的程度,彩色图片的预测率依旧高于50%。
这很有可能数据集中的两性具有一定的色彩特征。男性更常是在绿色草坪上,而数据集中的女性更常拥有更亮色的皮肤。
5. 人和背景
前序工作中已经证明人物的样貌一定包含了性别伪影。那么更朴素的问题是,是否图片背景,甚至是更高阶的人物信息(姿势和大小等)会包含人物伪影?
我们设置了一系列的遮挡图片来对比对预测度的影响,术语解释如下:
- Full:人物完全被显示出来
- Full NoBg:人物完全被显示并且没有背景
- MaskSegm:人物掩膜
- MaskRect:矩形掩膜
最终结果如下图
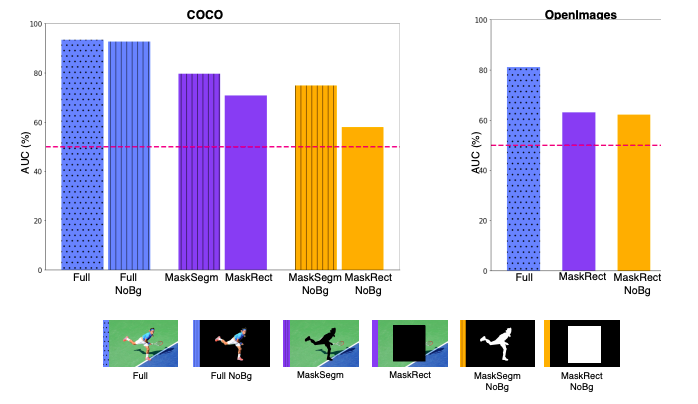
人物外貌是性别伪影。很明显,即使遮挡住背景时(Full Nobg),预测度也没有剧烈的下降。
仅仅使用人物的形状和位置对性别进行预测也达到了50%以上。我们看到即使在MaskSegm NoBg的情况下,也达到了74.8%的准确率,说明人物形状本身都能揭露性别情报,比如着装或是头发的长短。接下来,我们删除了更多人物信息,只留下了关键点(keypoints)如下图。

它们的表现依旧优于50%达到了64.8%的准确度。男性的动作有可能被模型认为更小和在运动状态;而女性更多的被模型认为倾向于更大和站立。
这些不同性别表达中的大小和位置差异是可被学习的。即使我们把人物轮廓遮住(MaskRectNoBg),结果仍表现出了高于50%的精度。
背景信息仍旧是极其重要的信息对于表达性别信息。因此任何仅仅只是通过遮挡人物外貌的方法,只不过是把性别伪影从人物转移到了背景上,实际上是无法真正消除所有性别伪影的。
定性分析。为了进一步理解背景中的性别伪影,我们进行了一系列定性分析结果如下图。
模型倾向于将城市和室内的背景与女性连接起来,而将室外和运动背景与男性结合。此外,通过第四行我们发现状态更“小”和静止时常被模型认为是女性,而“大”和动态被认为是男性。但是,我们也发现了如果人物外貌被包含在图片里时,运动的女性和静止的男性也是可以被正确区分的。
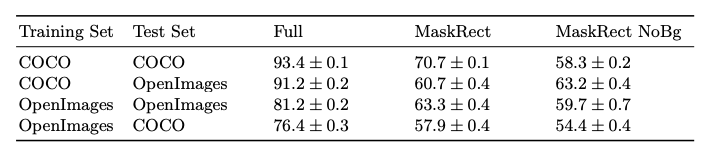
性别伪影在数据集中具有普遍性。我们对两个数据集进行了交叉验证如下表,不管是哪种掩膜设定最终结果都高于50%。
6. 具有语义内容的物体
这一章节我们致力于更好的理解性别伪影,并区别背景中的两大要素:物体和场景。
通过模型的关注度可视化性别伪影。我们使用CAMS可视化了不同物体在用于性别分类时的重要度,如下图
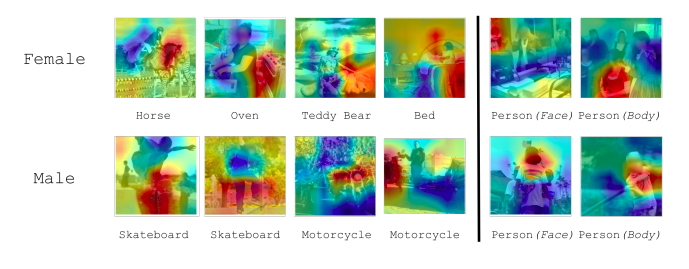
当人物被预测为女性时,模型在关注室内的物体如床和烤箱;而被预测为男性时,模型关注于室外物体如滑板和摩托。
和性别分类最有关的物体排序。在COCO中,比重最高的十个物体对应用于分类女性的,分别为吹风机,手提包,泰迪熊,雨伞和床;而比重最低的十个物体对应于分类男性,为滑板,领带,滑雪板,棒球手套和摩托车。
为了进一步理解这些物体的作用,我们逐步从图片中删除各个物体,并观察预测结果的准确率的变化。结果如下图。
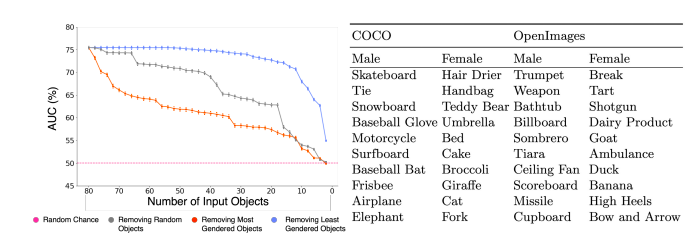
我们可以看到,物体产生的影响无处不在;直到我们将物体删除到一个不剩,判定率才下降到了50%的基准。
7. 讨论
首先,我们应该面对这种数据集中的不均匀而不是妄图消灭它们(我们已经证明了这几乎不可能)。因此使用注重公平性的模型是更好的选择。
此外,在构建数据集时我们也要尽量避免这种产生的偏差。我们应提前考虑这种结构是否会影响到下游任务的结果。
最后,我们应该警惕模型的学习结果。也许一些模型的结果真的和人类的判断结果相符合,甚至和我们的认知对应。但实际上它可能只是在学习这个数据集中的可视化物体的关联性,而不是真正的“理解”。当我们对结果分析时,我们应该小心我们的分析是不是其实仅仅是人类自己“赋予”的。