
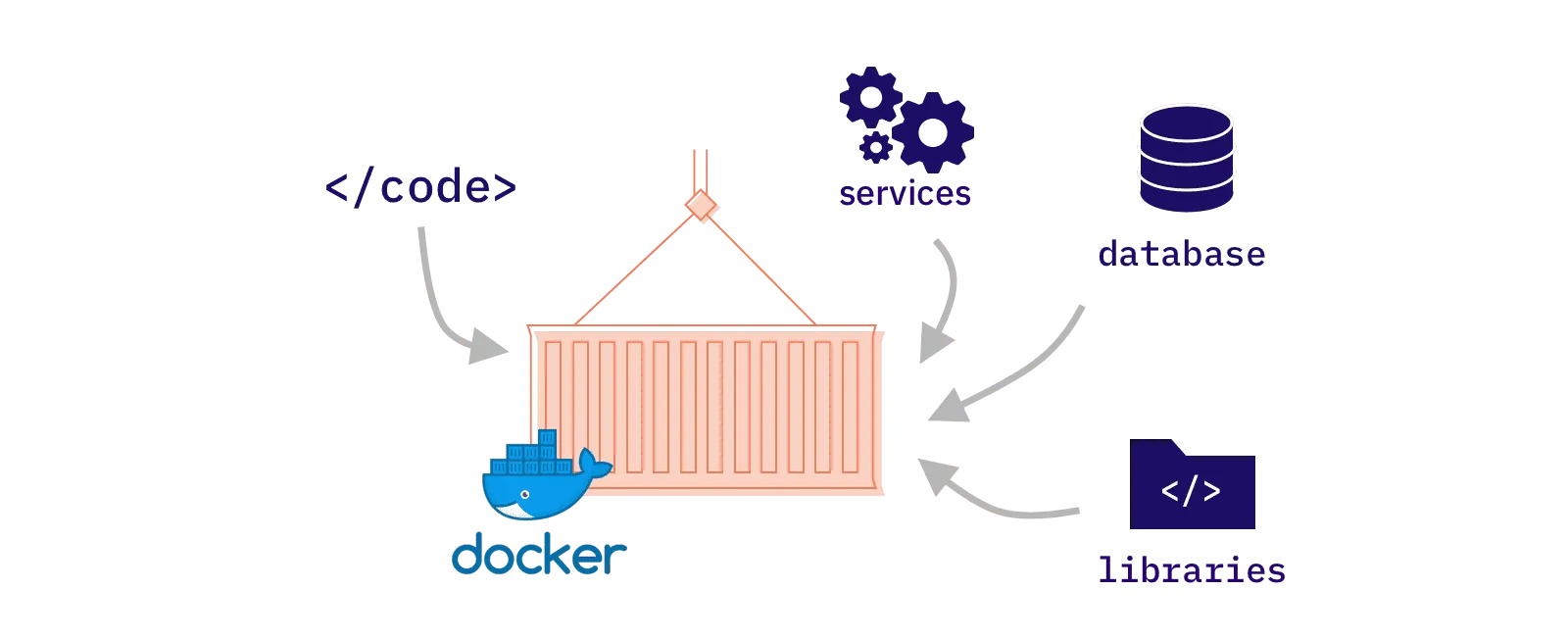
Docker+Flask=API application
ちょっと触っただけので大した内容ではなくて、各部分の基本構成とロジックをまとめる文章です
何がうれしい
Dockerは、依頼関係をパッケージ化することができるもので、実行するデバイスを変えても環境設定は要らない(例えAIプログラムを実行するときに必要なモデルとInputも、パッケージ化されている)
WSLは、Windows Subsystem for Linuxで、windowsOSでLinuxを実行するように最適化された仮想マシンです。これでLinuxと同じように使える。
Flask:Python用のウェブアプリケーションフレームワークです。PythonだけでAPIを構築できる。
環境設定一番苦労するところかも。。。
WSL2https://learn.microsoft.com/ja-jp/windows/wsl/install#step-4---download-the-linux-kernel-update-package
ここは特に記憶はないから、多分難しくない
Ubuntu普通のネットワークの下のならAppStoreから簡単に落とせるが、例えばセキュリ ...
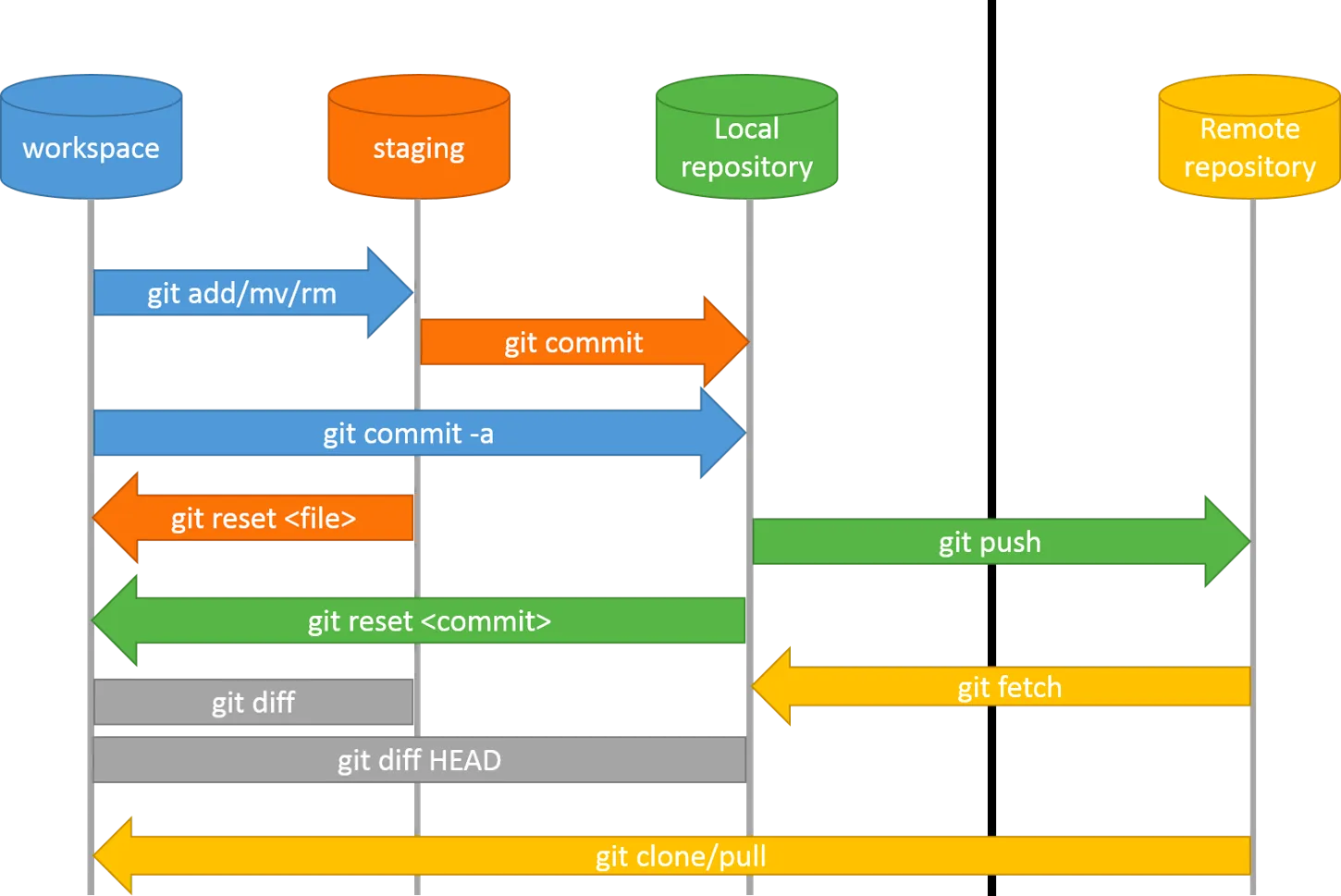
Git command and GUI 操作
基本リポジトリを初期化
git init
.gitのフォルダが作成され
gitが要らなくなる時に./gitを消せばいい
.gitignore
初期化するときに一緒に作るファイル。フォルダの中にどのようなファイルは追跡しなくてもいいをあらかじめ定義する
.tar.zip
ファイルのステージング
git add <file1> <file2>
ステージングされたファイルをコミットする(コメントを残して提出)
git commit -m “comment”
GUIを使うほうがやりやすい。
GitHubと連結する場合にはGithubで新しいリポジトリを作成して、手順通りにやればいい
git push
ブランチ別のブランチを作成:新しいfeatureや機能を作るとき、他人と共同作業をするとき。新しいブランチは、現時点のmainブランチをベースにして作成されたものです(つまり中身は一緒)。
git checkout -b <branch_name>
切り替える:git checkout <branch_name>
Github利用するときはG ...

PCに複数のCUDA環境を作る
最近は仕事関係でtensorflowに触れ始めたが、色々慣れない操作やトラップがあって、まだ忘れていないうちに記録する
PCに複数のCUDA環境を作るTFをインストールしようと思った時、なんと…
windows OSでTF-gpuをデプロイしたいならば、最高でも2.10しかない。もっと高いバージョンを使いたいならば、WSLのUBUTUNディストリビューションを使う他ない。(WSL2のブログまだ中途半端なのであまり自信ない・・・)
公開されているTFモデルでもこれから検証しようモデルでも、どちらでも結構古いモデルが多い気がする。だから古いTFでも対応できるはずかなという気持ちで、今度TF2.10.0のインストールを目指す。
GUDA要件確認GPUに依存するライブラリをインストールする前に必ず確認するもの
対応するCUDAバージョン
対応するcudnnバージョン
他の依頼関係
必ずどこかにある。ホームページではパッとわかる場所ではないが、Googleすれば出る。tensorflowはソースからビルトでCUDAバージョン要件を見つけられる。
https://www.tensorflow. ...

PytorchGPUとCPUでモデルを実行するについて
モデルの切り替えdevice = torch.device("cuda:0"/"cpu")model.to(device)data.to(device)
GPUの特徴非同期GPUは並列化処理ができるため、複数のタスクを同時に進めることが可能になります。
https://miro.medium.com/v2/resize:fit:1100/format:webp/0*T6wK4QDVadTLbIl-
It may makes:
GPU実行はまだ終わってないのに、end=time.time()は実行された
Warm-upが必須
warm-up = dry-on空運転は一回必要
the main reason for a dry-run is to put your CPU and GPU on maximum performance state
ベストパフォーマンスに至るまでに計測するのは正確でない
e.g. 計算が始まってから少し時間を空けて計測を始める
空運転の方法
CPU and GPU are very quick to ...

Diffusion model 总结
从去年diffusion的崛起陆陆续续的看了很多文章和应用,也有在自己的研究上加入一些元素。但是浑浑噩噩下来其实对于dm的历史以及进化过程很是浅显, 笔记也非常零碎,借此文章对笔记进行一些整理
符号T:定量。确定的时间步长。
t:变量。对应的时间步。
生成模型生成模型的根本其实就是:将训练数据和生成数据的分布尽可能接近
如果将一个个的sample看做是一个个人类,那么控制的参数则有性别,年龄,身高,器官的大小……这些数据的分布情况都决定了AI创造的的新种族是否与人类相似。如果这个种族的平均身高只有120,那必然怎么看都只能算侏儒群体。
将两个数据的分布靠近的方法可以分为下面两类:
直接计算:
严密计算:Flow-based
使用易于计算的上限值计算:VAE,diffusion
间接达成
GAN
在两种方法中,以GAN为首的间接达成的方法曾经一直是主流。其通过增加分辨器的方式进行对抗学习,”逼迫“生成器必须提取非常抽象的特征以生成无法被识别出来真假的sample。但是它的缺点是不够精细,生成样本的质量参差不齐。最近以Diffusion为主的直接计算法又再次登上舞台,但是只 ...

提示工程 | Prompt Engineering
课程:https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/
课程代码:https://github.com/ArslanKAS/Prompt-Engineering-by-OpenAI
文档:https://platform.openai.com/docs/api-reference/introduction
Overview
clear not equal short。有时必要的增加prompt的长度能下达更精准的命令。
使用区分符号如三引号,tag符号等。避免对模型产生误导。
解决复杂问题时要引导模型step by step的解决问题。模型有跳过说明性文字而直接看结果的倾向,可能导致错误答案。
要给模型思考时间。如提示他直到计算出答案前不要决定结果。
避免让模型直接生成名字等。模型有生成不存在的答案的倾向。必要时可以向模型提供相关的情报信息引导它生成真实存在的名字。
提示工程和深度学习的过程一样,是递归的。我们应该根据具体问题具体分析,在一次次的实验中找到最优prom ...
【花书】从概率统计到深度网络的概率预测
参考深度学习花书
第三章 概率与信息论【常用统计量,分布】
第五章 机器学习基础【参数选择,最大似然估计】
第六章 深度前馈网络【输出单元】
概率统计期望离散: $E[f(x)]=\sum_xP(x)f(x)$
连续: $E[f(x)]=\int P(x)f(x)dx$
默认地,我们假设E表示对括号内的所有随机变量求平均
性质:线性
E(af(x)+bg(x)+c)=aE(f(x))+bE(g(x))+c方差对x依照概率分布采样时,随机变量x的函数值会呈现多大的差异
离散: Var(f(x))=E[(f(x)-E[f(x)])^2]
协方差两个变量线性相关性的强度以及这些变量的尺度
Cov(f(x),g(y))=E[(f(x)-E[f(x)])(g(y)-E[g(y)])]随机变量组成的向量之间可构成协方差矩阵,其对角元素为方差
Cov(x)_{i,j}=Cov(x_i, x_j)
变量的尺度:1. 绝对值越大,变化越大 2. 若为正,则两个变量都倾向于取较于均值更大的值
相关性:若为0,则无线性相关;若不为0,则一定相关
注意:相关性比独立性的要求更弱。相关性无法判断非线性相关性,而 ...
【花书】从函数梯度到深度学习的优化算法
参考深度学习花书
第四章 数值计算【梯度下降,约束优化】
第八章 深度学习中的优化【优化问题,优化算法】
主要整理了1. 梯度的定义和性质,以及如何运用到寻找函数的极值点 2. 寻找极值点中,如果我们需要添加额外条件,需要使用到约束优化 3. 深度网络的优化学习中的挑战和应用 4. 基于梯度,当今流行的深度网络优化算法
梯度梯度定义梯度不仅可以表现为一个函数 $y=f(x)$,他的定义式还可以解读为“表明如何缩放输入的小变化才能在输出获得相应的变化”:
f(x+\epsilon) \approx f(x)+\epsilon f'(x)因此梯度对我们的优化问题非常有用:她告诉我们如何通过更改x来略微的调整y → 梯度下降法
一次梯度当我们有多个输入(一个函数多个变量)时,梯度是元素为 $\frac{\partial}{\partial x_i}f(x)$ 的向量
当我们有多个输入和多个输出 (多个函数多个变量)时
Jacobian 矩阵:相比于只有多个输入的情况,我们将同一个输出函数对于不同的变量的偏导写到行上,不同输出函数写到列上;因此构成了矩阵
J=\frac{\partia ...

【强化学习】chatGPT的工作原理
内容参考:
[1] How ChatGPT actually works : https://www.assemblyai.com/blog/how-chatgpt-actually-works/?continueFlag=49271bb2584143248da2304817eb2d87
[2] 强化学习一基础部分 : https://zhuanlan.zhihu.com/p/555303537
术语说明
Capability(能力)
Allignment(对齐性/泛化性)
传统语言模型的缺陷现在流行的语言模型训练方式有Next-token-prediction (下文预测)和 masked-language-modeling (遮挡预测), 如大名鼎鼎的transformer。这种方式使得模型能够学习完美构成的语句,却无法真正理解更高级别的语义内容。其特点是能力高,泛化度低。比起人类的复杂的判断系统(语境,常识等),语言模型更多而仅仅依靠上下文的出现概率(likelihood)进行判断。常见的缺点有:
缺少帮助性:无法遵循人类的指引(Instroduction)
捏造性:错误信 ...
剑指Offer-2(动态算法)
求解决策过程(decision process)最优化的数学方法。
剑指10-1. 斐波那契数列写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N))。斐波那契数列的定义如下:F(0) = 0, F(1) = 1F(N) = F(N - 1) + F(N - 2), 其中 N > 1.斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
避免重复计算因此使用动态算法
class Solution: def fib(self, n: int) -> int: a, b = 0, 1 for _ in range(n): a, b = b, a + b return a % 1000000007
剑指10-2. 青蛙跳台阶一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。答案需要取模 1e ...